模型评价体系
-

监管知识解析深
鑫鸿大模型以监管知识为核心,通过深度学习和自然语言处理技术,可深度解析监管政策、法规和相关文件。同时结合人工智能技术,能够智能化识别潜在的监管风险和合规问题。
-

评价体系优
鑫鸿大模型采用开放式框架,可纳入各类监管数据处理模型,并跟踪舆情处理类模型的最新进展,逐步构建决策树,支持向量机等模型库,形成适应监管报送及业务风险处理的模型评价体系。
-

训练效率高
鑫鸿大数据平台集成了主流基础组件,通过多条标准化流水线,可微调训练实现自动化流转,支持多模型并行训练,并采用主流加速框架,解决模型与数据并行难题,大幅提升训练及推理效率。
-
数据梳理难
机构数据种类多、来源多、口径不一致,不同来源的数据信息不互通、梳理数据的标准繁多、且标准细节难统一,梳理数据的工作量巨大、效率低下。
-
数据报送难
监管的报送政策是基于全部金融机构的特征统一制定,对某类机构自身的特色数据如何报送,需要经过多方分析才能整理出符合条件的数据,且监管报送的规则调整频繁、要求逐步增高,时间紧迫,自身难以形成完善的报送规范。
-
数据准确难
手工整理、计算数据,往往容易出现算错、漏算、未及时算出的情况,难以保证数据的准确性和及时性,这样算出的数据无法为机构提供业务方案制定指导。
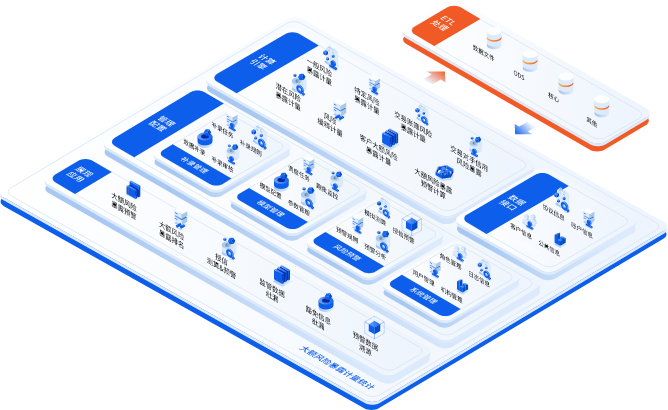
-
数据源接入层
鑫鸿大模型广泛收集监管机构文档类,实时交易类,资讯及舆情类等各类最新数据,用于模型训练及深度学习。
-
模型处理层
鑫鸿大模型通过对数据进行清洗,数据预处理,数据转换,以及模型处理等方式,进行深度学习。
-
模型功能
鑫鸿大模型通过问题回答,对话生成,文本生成,情感分析,信息检索,知识查询等功能,为金融机构日常经营提供快速,优质的资讯及信息服务。
-

自然语言处理
鑫鸿大模型通过自然语言处理,可对输入内容进行有效分析,输出内容包括但不限于问题答案,概念解释,解决方案等内容。
-

语义理解
鑫鸿大模型通过高强度的模型训练,可对输入的文本进行有效的语义理解并输出。
-

关联规则设置
鑫鸿大模型可对输入内容进行有效识别,按照输入要求生成对应的文本内容,包括但不限于摘要,段落,文章等。
-
数据披露
鑫鸿大模型可根据已学习到的内容,结合数据库中所存在的知识及模型,提供理解查询,文本检索,关键字匹配,提供信息来源等服务。